Python在Spark上的机器学习(一)之环境搭建
前面已经介绍了不少机器学习的算法了,那么机器学习又该如何结合大数据一起使用么?
常言道:工欲善其事,必先利其器
既然来结合大数据与机器学习,我们就不得不提Spark了。
首先,Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
讲了这么多Spark的优点,那么现在我们就先开始来搭建一个Spark 集群环境吧!
安装基础环境
1. Java1.8环境搭建(下载JDK1.8的):
下载页面:
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
安装过程可以参考Linux公社给出的教程
Ubuntu用户:
Ubuntu用户可以通过添加PPA源再通过Apt来进行安装
$ sudo add-apt-repository ppa:webupd8team/java
$ sudo apt-get update
$ sudo apt-get install oracle-java8-installer
2. Scala环境搭建
下载scala安装包:
wget -O "scala-2.12.3.deb"
https://downloads.lightbend.com/scala/2.12.3/scala-2.12.3.deb
或者
wget -O "scala-2.12.3.rpm" "https://downloads.lightbend.com/scala/2.12.3/scala-2.12.3.rpm"
安装deb/rpm包:
rpm -ivh scala-2.12.3.rpm
dpkg -i scala-2.12.3.deb增加SCALA_HOME
$ vim /etc/profile
增加如下内容;
export SCALA_HOME=/usr/share/scala
刷新配置
$ source /etc/profile
安装Hadoop
1.下载二进制包:
wget http://www-eu.apache.org/dist/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
2.解压并移动至相应目录:
我的习惯是将软件放置/opt目录下:
tar -xvf hadoop-2.7.3.tar.gz
mv hadoop-2.7.3 /opt
3.修改相应的配置文件:
(1) $ vim /etc/profile
增加如下内容:
#hadoop enviroment
export HADOOP_HOME=/opt/hadoop-2.7.3/
export PATH="$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH"
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop(2) $ vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
修改JAVA_HOME 如下:
export JAVA_HOME=<你的Java安装目录>
-
(3) $ vim $HADOOP_HOME/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.3/tmp</value>
</property>
</configuration>(4) $ vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop-2.7.3/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop-2.7.3/hdfs/data</value>
</property>
</configuration>(5) $ vim $HADOOP_HOME/etc/hadoop/mapred-site.xml
复制template,生成xml:
cp mapred-site.xml.template mapred-site.xml
内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:19888</value>
</property>
</configuration>(6) $ vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>至此master节点的hadoop搭建完毕
再启动之前我们需要
格式化一下namenode
$ hadoop namenode -format
安装Spark
下载文件:
wget -O "spark-2.1.0-bin-hadoop2.7.tgz" "http://d3kbcqa49mib13.cloudfront.net/spark-2.1.0-bin-hadoop2.7.tgz"解压并移动至相应的文件夹:
tar -xvf spark-2.1.0-bin-hadoop2.7.tgz
mv spark-2.1.0-bin-hadoop2.7 /opt
修改相应的配置文件:
(1) $ vim /etc/profie
#Spark enviroment
export SPARK_HOME=/opt/spark-2.1.0-bin-hadoop2.7/
export PATH="$SPARK_HOME/bin:$PATH"(2) $ vim $SPARK_HOME/conf/spark-env.sh
-
cp spark-env.sh.template spark-env.sh
#配置内容如下:
export SCALA_HOME=/usr/share/scala
export JAVA_HOME=<你的Java安装目录>
export SPARK_MASTER_IP=master
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/opt/hadoop-2.7.3/etc/hadoop至此,我们大部分环境基本安装完毕!
测试Spark
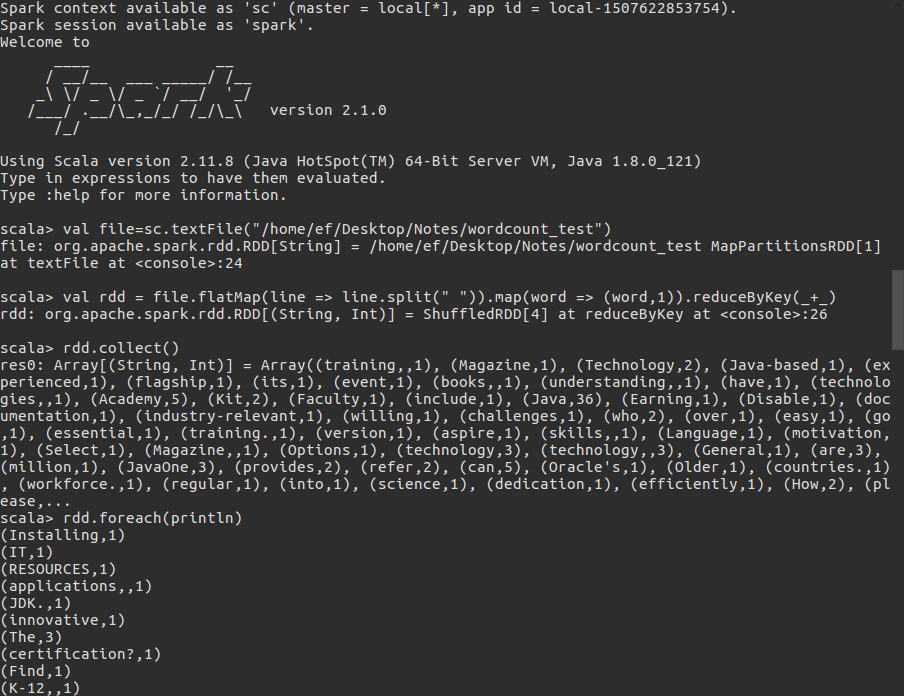
为了避免麻烦这里我们使用spark-shell以及本地的文件(非hdfs),做一个简单的worcount的测试。
val file=sc.textFile("/home/ef/Desktop/Notes/wordcount_test")
val rdd = file.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_)
rdd.collect()
rdd.foreach(println)展示图:
小结
到此,我们在Spark上进行机器学习训练的环境,就搭建完毕了,下章我们再开始讲Spark中的数据结构与Python中的区别,以及结合Pyspark来进行数据处理。