Magit 是 Emacs 下对git的封装,利用Magit可以让你在Emacs中即可完成对git仓库的管理(Emacs果然是一个伪装成编辑器的操作系统)
其次,Magit本不是Emacs的内置插件,使用时需要自己安装;具体的安装方法在Magit的官网上已经有相关教程了,这里我就不再赘述了
日常使用
下面主要是列举一些日常开发和git管理中比较常使用的一些功能:
1. M-x:magit-status(C-x g)
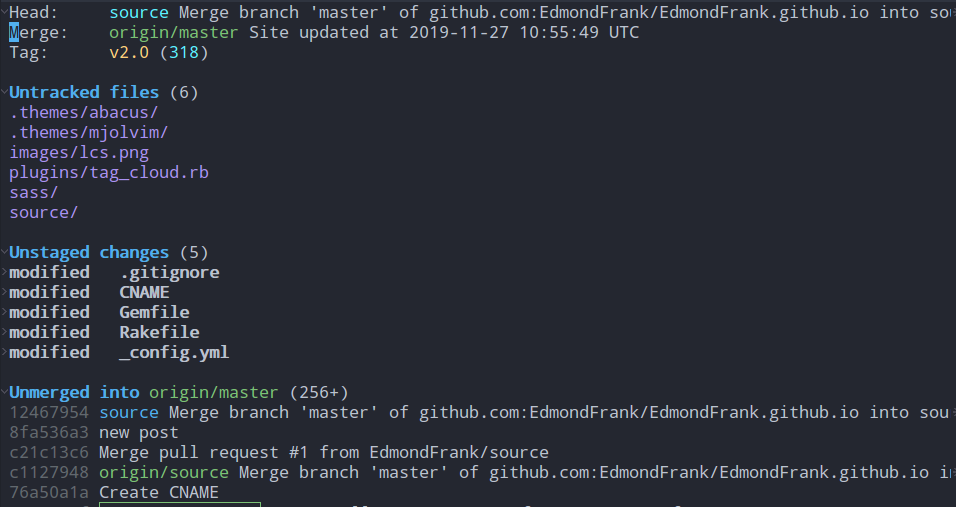 该命令就类似于git status(查看项目的当前状态);但是,在Magit中显示的状态信息会比git status更加丰富
其中包括:HEAD、Tag、未追踪文件、Stash列表、未staged文件、未push文件、最近commit等信息
然后,在相应的条目上回车还可以进行看到更加详细的内容,包括对应文件的修改、具体的commit信息等等
该命令就类似于git status(查看项目的当前状态);但是,在Magit中显示的状态信息会比git status更加丰富
其中包括:HEAD、Tag、未追踪文件、Stash列表、未staged文件、未push文件、最近commit等信息
然后,在相应的条目上回车还可以进行看到更加详细的内容,包括对应文件的修改、具体的commit信息等等
2. (?) Magit Help
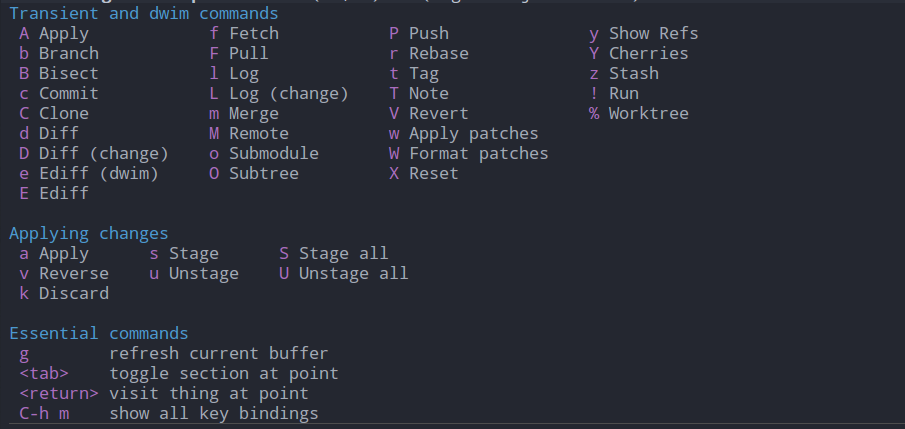 在magit status buffer中键入?可以提示Magit的功能列表以及其相对应的key bindings,新手通过这样一个帮助列表,就可以找到对应的git功能一一操作试试,一段时间后就可以熟悉整个magit的操作了
在magit status buffer中键入?可以提示Magit的功能列表以及其相对应的key bindings,新手通过这样一个帮助列表,就可以找到对应的git功能一一操作试试,一段时间后就可以熟悉整个magit的操作了
3. (s/S)Stage/Stage all
Stage命令就类似于git add操作,在你修改了相关的git管理下的文件后,若是还未运行git add时,该文件处于Unstaged的状态 处于Unstaged状态的文件在git commit的时候其变更内容就不会提交;而运行git add [filename] 之后文件就变成Stage状态了, 此时如果再执行git commit,对应的文件变更内容则提交到本地,然后文件状态变更未Unpushed
4. (u/U) Unstage/Unstage all
Unstage命令就是Stage命令的反向操作,其对应git reset HEAD [filename],在Magit中Stage/Unstage不仅能够作用于单个文件、所有的changes,还能作用于某个文件的部分区域上;在magit展开文件的diff时,你还发现在文件差异中用@@符号区分的差异区域,在对应的区域内键入Stage/Unstage命令即可仅仅存在该区域中的变更,然后在commit提交时,也可以单单提交这一部分变更
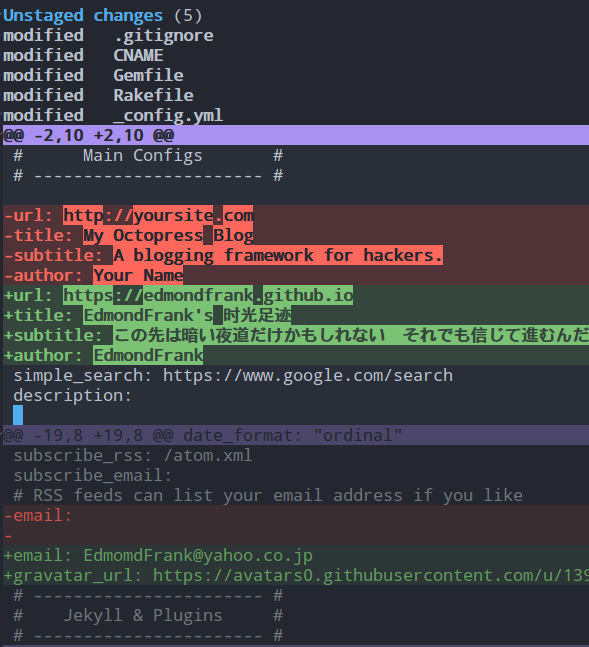
5. © Commit
在magit-status-buffer中键入c键即为最常用的git commit指令,当然后除了最普通的Commit(cc)操作外 Magit还支持许多commit的扩展命令
| key bindings | command | description |
|---|---|---|
| cc | Commit | 最普通的 git commit |
| ce | Extend | 当前Staged的文件合并到上一次提交中 git commit –amend –no-edit |
| ca | Amend | 只修改上次提交的日志 git commit –amend |
6. (F) Pull
Pull命令对应git pull在git管理中用于拉取远程仓库代码,常用的组合命令有以下:
| key bindings | description |
|---|---|
| Fu | pull from upstream |
| Fp | pull from pushremote |
| Fe | pull from elsewhere 会引导你从哪pull |
对于Fu 和 Fp来说,upstream是pushremote的上级,这样的场景对应fork分支开发的工作流; 比如User A 有个仓库 Project,User B fork了Project,这样对于User B来说 UserA/Project就是upstream,而pushremote是UserB/Project 另外,在Magit中只有设置了pushremote分支,这样magit status buffer才会显示有哪些变更没有push和pull
7. (P) Push
对应git push 命令
| key bindings | command | description |
|---|---|---|
| pu | push to upstream | 最普通的git push |
| pe | push to elsewhere | 会引导你push到哪个远程分支 |
| po | push another branch to | 会引导你push到哪个分支 |
| pT | push a tag | push 一个tag标签 |
| pt | push all tag | push 所有tag标签 |
除此之外,上面的key bindings组合还可以添加对应的扩展参数,比如强制push,即p-Fu
8. (l) Log查看日志
对应git log,查看git日志记录
| key bindings | description |
|---|---|
| ll | 查看当前分支的日志 |
| lo | log other 查看其他分支的日志 |
在具体的commit上使用 l 键还可以根据给出的命令组合进一步查看commit提交的详情信息
9. (a/A) cherry picking
对应git cherry-pick,选择某一次的commit在当前分支重新commit一次,适用于合并代码但又不想merge整个PR和分支的场景
10. (z)Stash
对应git Stash,将临时的未commit的变更内容暂存起来 常用命令有:
| key bindings | command | description |
|---|---|---|
| zz | git stash | 暂存 |
| zp | git stash pop | 恢复 |
除此之外,还有一个有意思的用法是,当你希望单单想stash变更文件列表中的一个文件时,可以先将目标文件Stage在index索引区,然后适用 zi 组合暂存index区域,这样就可以实现单一文件的stash功能
11. (k) Discard/Delete
对应git中的checkout之类的命令,用作于放弃更改和删除相关的操作,例如,放弃一个Unstage文件的更改、删除一个Stash、删除一个@@区域差异等等
12. (x) Resetting
类似git reset命令,放弃最近的n次提交,这n次的提交内容变成staged状态,之后可以进行合并提交或者丢弃 只需要在日志日光标定位到想要丢弃的log,即可回滚到这一次的提交状态
13. (m) Merge
对应git中合并分支的操作,常用的组合命令为 mm ,之后会提示选择与哪个分支进行merge
14. ® Rebase
对应git中的变基操作
| key bindings | description |
|---|---|
| ru | rebase on upstream |
| rp | rebase on pushremote |
| re | 会提示你以哪个分支为基点进行rebase |






















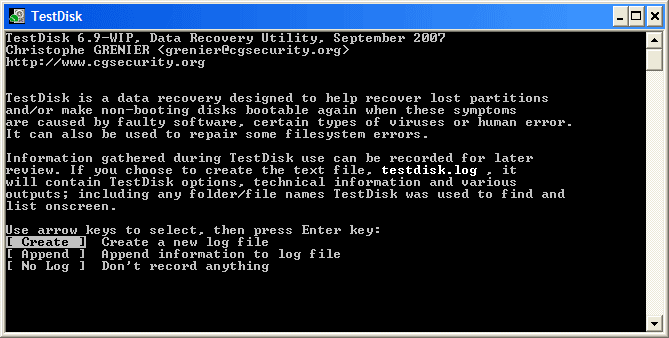
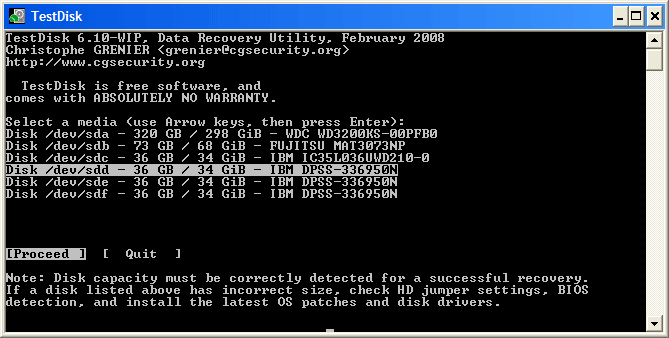
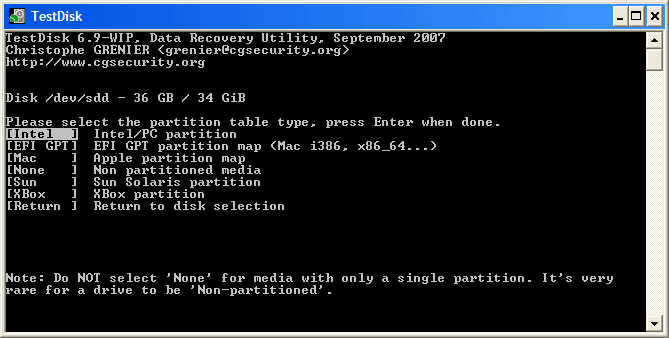
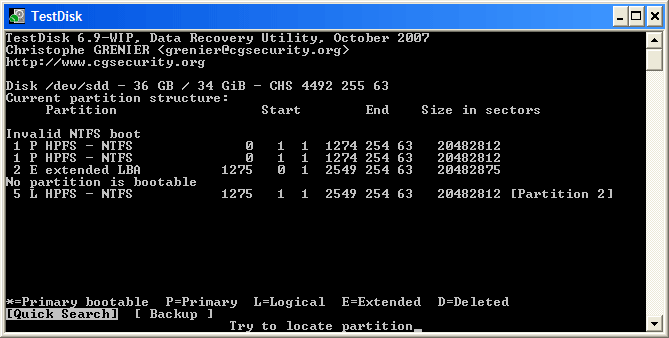
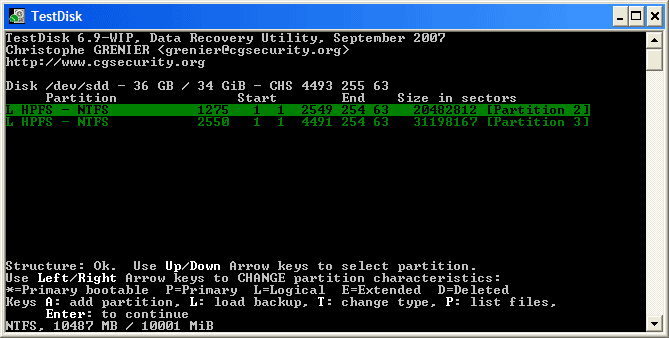 + 高亮这个分区并按 p 来列出文件 (若要返回前一页,请按 q ).
+ 这里所有的目录和文件都正确列出来了。
+ 按 Enter 键继续。
+
+ 高亮这个分区并按 p 来列出文件 (若要返回前一页,请按 q ).
+ 这里所有的目录和文件都正确列出来了。
+ 按 Enter 键继续。
+ 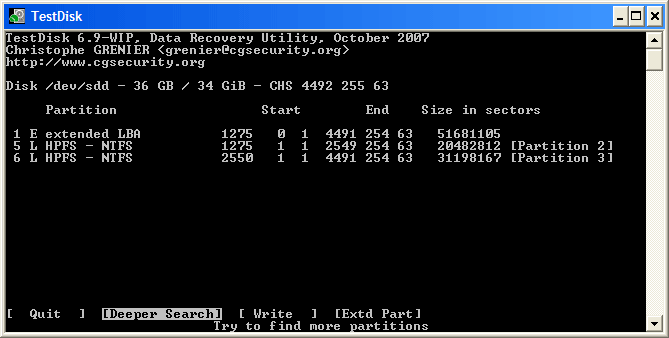 (经过笔者的几次实验和朋友的反馈,其实到了这一步已经能够解决80%以上的问题了!)
(经过笔者的几次实验和朋友的反馈,其实到了这一步已经能够解决80%以上的问题了!)