Python Keras + LSTM 进行单变量时间序列预测
首先,时间序列预测问题是一个复杂的预测模型问题,它不像一般的回归预测模型。时间序列预测的输入变量是一组按时间顺序的数字序列。它既具有延续性又具有随机性,所以在建模难度上相对回归预测更大。
但同时,正好有一种强大的神经网络适合处理这种存在依赖关系的序列问题:RNN(Recurrent neural networks)。在过去几年中,应用 RNN 在语音识别,语言建模,翻译,图片描述等问题上已经取得一定成功,并且应用领域还在扩展。
LSTM网络
Long Short-Term Memory 网络亦称LSTM 网络,是一种在深度学习中应用的循环神经网络。可以学习长期依赖信息。LSTM 由Hochreiter & Schmidhuber (1997)提出,并在近期被Alex Graves进行了改良和推广。在很多问题,LSTM 都取得相当巨大的成功,并得到了广泛的使用。LSTM 通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力。
具体应用
下面以一个洗发水销售的例子,来实现LSTM。 首先,你可以在这里下载到本文需要用的数据集。这是一个描述了3年内洗发水的月度销售数量的数据集。
数据读取
1 2 3 4 5 6 7 8 9 10 11 | |
数据划分
首先我们把数据集划分成两个部分即:训练集和测试集。 那么我们该如何划分呢?因为我们今天研究的是时间序列分析,所以在数据集的划分上我们也应该按照时间来划分。我们可以将前两年的数据作为我们的训练集而将最后一年的数据作为测试集。
1 2 3 | |
这里我们假设一个滚动预测的情景,又称前向模型验证(walk-forward model validation)。其原理很简单,举例来说就像当公司的预测期长达一年时,预测会将已过去的月份排除,而将预测期末的月份补上。好比一月份过去后,我们将其从预测中移除,同时次年的一月份就会作为收尾被添加到预测中以便预测总能保持12个月的完整性。
这样通过使用每月新的洗发水销售量来进行下个月的预测,我们就像模拟了一个更接近于真实世界的场景。
最后,我们将所有在测试集上的预测结果收集起来并计算出他们与真实值的均方根误差(RMSE)以此来作为评估我们模型的基准。
持续模型预测(Persistence Model Forecast)
持续性预测的基本思路就是从先前的(t-1)时间序列的结果用于预测当前时间(t)的取值。 那么根据以上的思路,我们可以通过滚动预测的原理从训练集的历史数据中获取最后一次观察值并使用它来预测当前时间的可能取值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | |
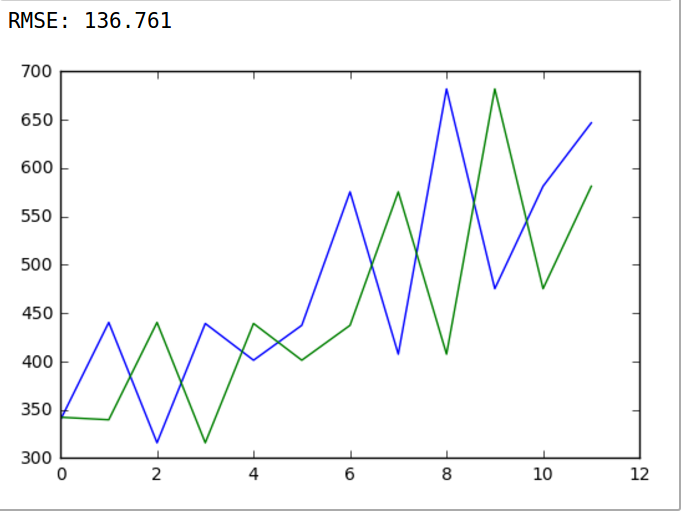
通过持续模型的预测,我们得到了一个最基础的预测模型以及RMSE(baseline)为了提升我们预测模型的效果,下面让我们进入正题来构建LSTM模型来对数据集进行时间序列预测。
数据处理
为了能够构建一个LSTM模型对训练集进行训练,我们首先要对数据进行一下处理:
- 将时间序列问题转化成监督学习问题
- 平稳时间序列
- 数据标准化
将时间序列转换成监督学习
对于一个时间序列问题,我们可以通过使用从最后一个(t-1)时刻的观测值作为输入的特征X和当前时刻(t)的观测值作为输出Y来实现转换。
因为,需要转换的是一组时间序列数据,所以无法组合成像真正的监督学习那样有明确一对一映射的输入输出关系。尤其是在数据集的最开始或最后时,两个位置总有一个位置无法在训练集中找到对应关系。为了解决这样的问题,我们通常的做法是,在最开始时将输入特征置为0,而它对应的输出就是时间序列的第一个元素。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
输出结果: 0 0 0 0.0 266.0 1 266.0 145.9 2 145.9 183.1 3 183.1 119.3 4 119.3 180.3 5 180.3 168.5 6 168.5 231.8 7 231.8 224.5 8 224.5 192.8 9 192.8 122.9 10 122.9 336.5 11 336.5 185.9 12 185.9 194.3 13 194.3 149.5 14 149.5 210.1 15 210.1 273.3 16 273.3 191.4 17 191.4 287.0 18 287.0 226.0 19 226.0 303.6 20 303.6 289.9 21 289.9 421.6 22 421.6 264.5 23 264.5 342.3 24 342.3 339.7 25 339.7 440.4 26 440.4 315.9 27 315.9 439.3 28 439.3 401.3 29 401.3 437.4 30 437.4 575.5 31 575.5 407.6 32 407.6 682.0 33 682.0 475.3 34 475.3 581.3 35 581.3 646.9
平稳时间序列
虽然不明显,但我们仍可以看出这个洗发水销售数据集在时间上呈上升趋势。因此我们说这个时间序列数据是非平稳的。那么,不平稳怎么办?
答案就是:差分。(有关差分的介绍点击此处)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | |
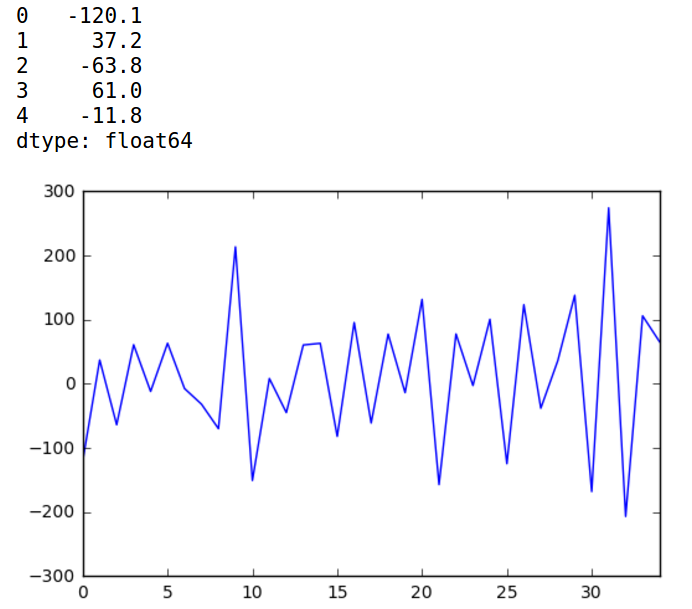
经过一阶差分处理后,从图上看还是挺平稳的。
标准化数据
在数据输入前进行标准化可以非常有效的提升收敛速度和效果。尤其如果我们的激活函数是sigmoid或者tanh,其梯度最大的区间是0附近,当输入值很大或者很小的时候,sigmoid或者tanh的变化就基本平坦了(sigmoid的导数sig(1-sig)会趋于0),也就是进行梯度下降进行优化的时候,梯度会趋于0,而倒是优化速度很慢。
如果输入不进行归一化,由于我们初始化的时候一般都是0均值的的正太分布或者小范围的均匀分布(Xavier),如果输入中存在着尺度相差很大的特征,例如(10000,0.001)这样的,很容易导致激活函数的输入w1x1+w2x2+b变的很大或者很小,从而引起梯度趋于0。
而LSTM的默认激活函数就是tanh函数,它的输出范围在-1 到 1 之间,同时这是时间序列数据的首选范围。因此我们可以使用MinMaxScaler类将数据集转换到范围[-1,1]。像其他scikit用于转换数据的方法类一样,它需要以行和列的矩阵格式提供的数据。因此,在转换之前,我们必须重塑NumPy数组。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
输出结果: Month 1901-01-01 266.0 1901-02-01 145.9 1901-03-01 183.1 1901-04-01 119.3 1901-05-01 180.3 Name: Sales of shampoo over a three year period, dtype: float64 0 -0.478585 1 -0.905456 2 -0.773236 3 -1.000000 4 -0.783188 dtype: float64 0 266.0 1 145.9 2 183.1 3 119.3 4 180.3 dtype: float64
构建LSTM模型
长短期记忆网络(LSTM)是一种递归神经网络(RNN)。 这类网络的的优点是它能学习并记住较长序列,并不依赖预先指定的窗口滞后观察值作为输入。 在Keras中,这被称为stateful,在定义LSTM网络层时将“stateful”语句设定为“True”。
LSTM层要求输入矩阵格式为:[样本,时间步长,特征]
鉴于训练数据集的形式定义为X输入和y输出,必须先将其转化为样本/时间步长/特征的形式。
完整代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 | |
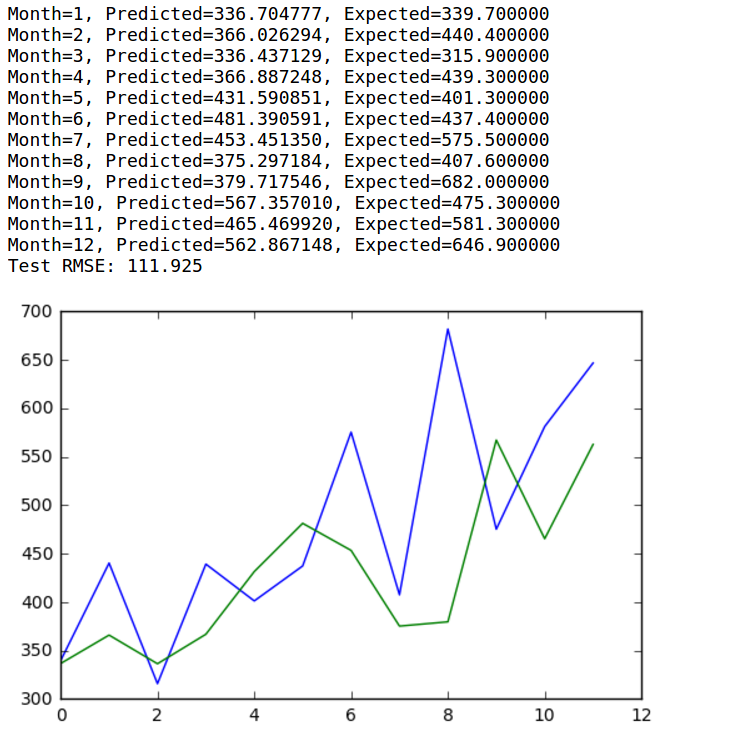
最后运行结果打印出测试数据集12个月份中每个月份的预期和预测销量。示例还打印了所有预测值得均方根误差。该模型显示洗发水月度销量的均方根误差为111.925,好于持续性模型得出的对应结果136.761。
另外,神经网络的一个难题是初始条件不同,它们给出结果就不同。一种解决办法是修改Keras使用的随机数种子值以确保结果可复制。另一种办法是使用不同的实验设置控制随机初始条件。