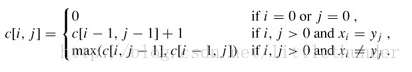#params:# - a : str# - b : str#return# - c : 过程处理矩阵# - c[x][y] : the lcs-length(最长公共子序列长度)deflcs(a,b):lena=len(a)lenb=len(b)c=[[0foriinrange(lenb+1)]forjinrange(lena+1)]foriinrange(lena):forjinrange(lenb):ifa[i]==b[j]:c[i+1][j+1]=c[i][j]+1elifc[i+1][j]>c[i][j+1]:c[i+1][j+1]=c[i+1][j]else:c[i+1][j+1]=c[i][j+1]returnc,c[lena][lenb]
网页相似度计算
1234567891011121314151617181920212223
#-*-coding:utf-8-*-importlxml.html.soupparserassoupparserimportrequestsheaders={"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36"}defget_domtree(html):dom=soupparser.fromstring(html)forchildindom.iter():yieldchild.tagdefsimilar_web(a_url,b_url):html1=requests.get(a_url,headers=headers).texthtml2=requests.get(b_url,headers=headers).textdom_tree1=">".join(list(filter(lambdae:isinstance(e,str),list(get_domtree(html1)))))dom_tree2=">".join(list(filter(lambdae:isinstance(e,str),list(get_domtree(html2)))))c,flag,length=lcs(dom_tree1,dom_tree2)return2.0*length/(len(dom_tree1)+len(dom_tree2))percent=similar_web('http://edmondfrank.github.io/blog/2017/04/05/qian-tan-mongodb/','http://edmondfrank.github.io/blog/2017/03/27/emacsshi-yong-zhi-nan/')print(percent)#相似度(百分比)