# encoding=utf-8importredisfromhashlibimportmd5classSimpleHash(object):def__init__(self,cap,seed):self.cap=capself.seed=seeddefhash(self,value):ret=0foriinrange(len(value)):ret+=self.seed*ret+ord(value[i])return(self.cap-1)&retclassBloomFilter(object):def__init__(self,host='localhost',port=6379,db=0,blockNum=1,key='bloomfilter'):""" :param host: the host of Redis :param port: the port of Redis :param db: witch db in Redis :param blockNum: one blockNum for about 90,000,000; if you have more strings for filtering, increase it. :param key: the key's name in Redis """self.server=redis.Redis(host=host,port=port,db=db)self.bit_size=1<<31# Redis的String类型最大容量为512M,现使用256Mself.seeds=[5,7,11,13,31,37,61]self.key=keyself.blockNum=blockNumself.hashfunc=[]forseedinself.seeds:self.hashfunc.append(SimpleHash(self.bit_size,seed))defisContains(self,str_input):ifnotstr_input:returnFalsem5=md5()m5.update(str_input)str_input=m5.hexdigest()ret=Truename=self.key+str(int(str_input[0:2],16)%self.blockNum)forfinself.hashfunc:loc=f.hash(str_input)ret=ret&self.server.getbit(name,loc)returnretdefinsert(self,str_input):m5=md5()m5.update(str_input)str_input=m5.hexdigest()name=self.key+str(int(str_input[0:2],16)%self.blockNum)forfinself.hashfunc:loc=f.hash(str_input)self.server.setbit(name,loc,1)if__name__=='__main__':""" 第一次运行时会显示 not exists!,之后再运行会显示 exists! """bf=BloomFilter()ifbf.isContains('http://www.baidu.com'):# 判断字符串是否存在print'exists!'else:print'not exists!'bf.insert('http://www.baidu.com')
importrandomdefloaddata(filename):dataMat=[]withopen(filename)asfp:forlineinfp.readlines():dataMat.append(line.strip().split('\t'))returndataMatdefsimple_sampling(dataMat,num):try:samples=random.sample(dataMat,num)returnsamplesexcept:print('sample larger than population')
defpca(dataMat,topNfeat=9999999):meanVals=np.mean(dataMat,axis=0)#print(meanVals)meanRemoved=dataMat-meanVals#remove mean#print(meanRemoved)covMat=np.cov(meanRemoved,rowvar=0)eigvals,eigvects=np.linalg.eig(np.mat(covMat))#计算协方差矩阵的特征值和特征向量eig_valind=np.argsort(eigvals)#sort, sort goes smallest to largesteig_valind=eig_valind[:-(topNfeat+1):-1]#cut off unwanted dimensionsred_eigvects=eigvects[:,eig_valind]#reorganize eig vects largest to smallestlow_datamat=meanRemoved*red_eigvects#transform data into new dimensionsreconmat=(low_datamat*red_eigvects.T)+meanValsreturnlow_datamat,reconmat
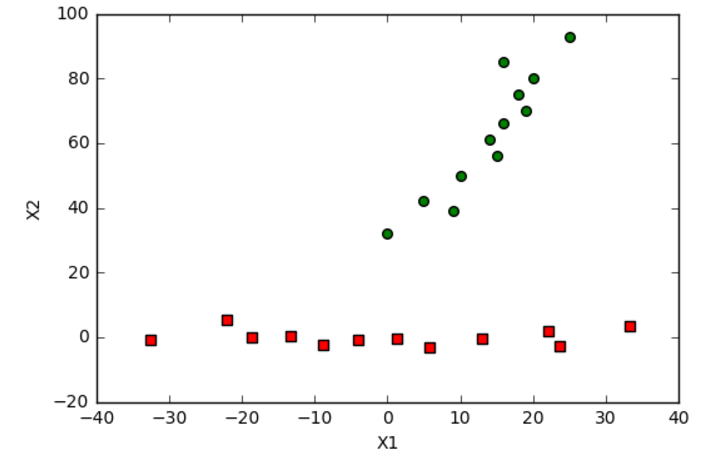
importnumpyasnpimportmatplotlib.pyplotaspltdefloadDataSet(fileName,delim='\t'):fr=open(fileName)stringArr=[line.strip().split(delim)forlineinfr.readlines()]datArr=[list(map(float,line))forlineinstringArr]#print(mat(datArr))fr.close()returnnp.mat(datArr)defpca(dataMat,topNfeat=9999999):meanVals=np.mean(dataMat,axis=0)#print(meanVals)meanRemoved=dataMat-meanVals#remove mean#print(meanRemoved)covMat=np.cov(meanRemoved,rowvar=0)eigvals,eigvects=np.linalg.eig(np.mat(covMat))#计算协方差矩阵的特征值和特征向量eig_valind=np.argsort(eigvals)#sort, sort goes smallest to largesteig_valind=eig_valind[:-(topNfeat+1):-1]#cut off unwanted dimensionsred_eigvects=eigvects[:,eig_valind]#reorganize eig vects largest to smallestlow_datamat=meanRemoved*red_eigvects#transform data into new dimensionsreconmat=(low_datamat*red_eigvects.T)+meanValsreturnlow_datamat,reconmatdefplotBestFit(dataSet1,dataSet2):dataArr1=np.array(dataSet1)dataArr2=np.array(dataSet2)n=np.shape(dataArr1)[0]n1=shape(dataArr2)[0]xcord1=[];ycord1=[]xcord2=[];ycord2=[]xcord3=[];ycord3=[]j=0foriinrange(n):xcord1.append(dataArr1[i,0]);ycord1.append(dataArr1[i,1])xcord2.append(dataArr2[i,0]);ycord2.append(dataArr2[i,1])fig=plt.figure()ax=fig.add_subplot(111)ax.scatter(xcord1,ycord1,s=30,c='red',marker='s')ax.scatter(xcord2,ycord2,s=30,c='green')plt.xlabel('X1');plt.ylabel('X2');plt.show()if__name__=='__main__':mata=loadDataSet('score')a,b=pca(mata,4)plotBestFit(a,b)