Scala 的概率编程语言库-Figaro
什么是概率编程?
概率编程是一种系统创建方法,它所创建的系统能够帮助我们在面对不确定性时作出决策。
为什么使用概率编程?
概率推理是机器学习的基础技术之一。Google,Amazon和Microsoft等公司使用它理解可用数据。概率推理已经应用于各种各样的应用程序,如预测股价,推荐电影,诊断计算机和检测网络入侵。
- 概率推理可用于预测未来,推断过去,以及从过去的事实中学习更好地预测未来。
- 概率编程是使用图灵完备的编程语言作为表示语言的概率编程。
事实上:概率推理 + 图灵完备 = 概率编程
Figaro的简介
Figaro是一个内嵌于Scala编程语言的概率编程系统。除了继承了Scala的良好特性外,Figaro还提供了相当多的额外的优势,包括:
- Figaro能够表示及其广泛的概率模型。Figaro元素的值可以为任何类型,包括布尔型,整数,双精度数,数组,树,图等。
- Figaro提供了使用其条件和约束规定证据的丰富框架
- Figaro有多种多样的推理算法
- Figaro能够表示和推理随时间变化的的动态模型
- Figaro能够在其模型中包含明确决策,并支持最优决策的推断。
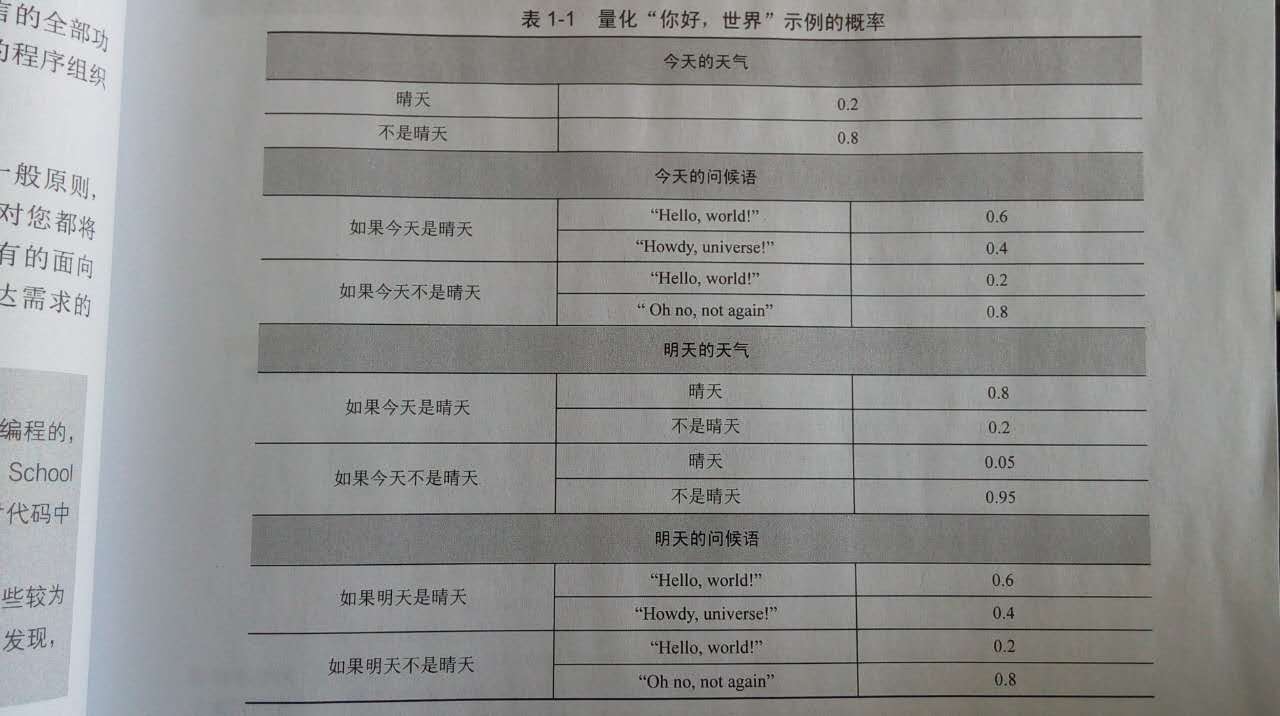
简单示例-量化“你好,世界”
图片截取自《概率编程实战》 表 1-1
代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | |