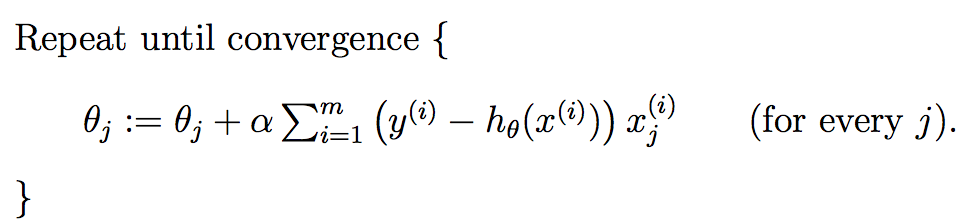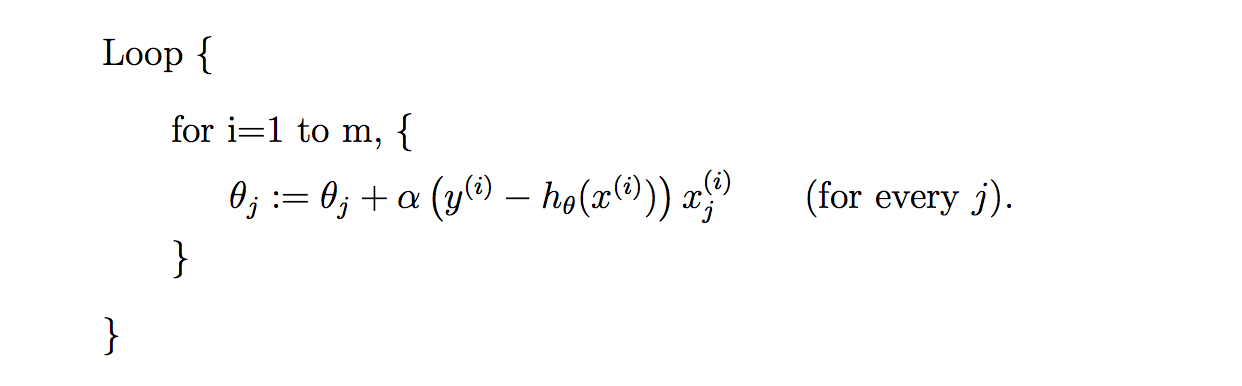#Training data set#each element in x represents (x0,x1,x2)x=[(1,0.,3),(1,1.,3),(1,2.,3),(1,3.,2),(1,4.,4)]#y[i] is the output of y = theta0 * x[0] + theta1 * x[1] +theta2 * x[2]y=[95.364,97.217205,75.195834,60.105519,49.342380]epsilon=0.0001#learning ratealpha=0.01diff=[0,0]error1=0error0=0m=len(x)#init the parameters to zerotheta0=0theta1=0theta2=0whileTrue:#calculate the parametersforiinrange(m):diff[0]=y[i]-(theta0+theta1*x[i][1]+theta2*x[i][2])theta0=theta0+alpha*diff[0]*x[i][0]theta1=theta1+alpha*diff[0]*x[i][1]theta2=theta2+alpha*diff[0]*x[i][2]#calculate the cost functionerror1=0forlpinrange(len(x)):error1+=(y[i]-(theta0+theta1*x[i][1]+theta2*x[i][2]))**2/2ifabs(error1-error0)<epsilon:breakelse:error0=error1print(' theta0 : %f, theta1 : %f, theta2 : %f, error1 : %f'%(theta0,theta1,theta2,error1))print('Done: theta0 : %f, theta1 : %f, theta2 : %f'%(theta0,theta1,theta2))
importnumpyasnpimportpandasaspdheader=['user_id','item_id','rating','timestamp']df=pd.read_csv('/home/ef/Desktop/ml-100k/u.data',sep='\t',names=header)print(df.head())n_users=df.user_id.unique().shape[0]n_items=df.item_id.unique().shape[0]print('Number of users = '+str(n_users)+' | Number of movies = '+str(n_items))
输出结果:
user_id item_id rating timestamp
0 196 242 3 881250949
1 186 302 3 891717742
2 22 377 1 878887116
3 244 51 2 880606923
4 166 346 1 886397596
Number of users = 943 | Number of movies = 1682
fromsklearn.metricsimportmean_squared_errorfrommathimportsqrtdefrmse(prediction,ground_truth):prediction=prediction[ground_truth.nonzero()].flatten()ground_truth=ground_truth[ground_truth.nonzero()].flatten()returnsqrt(mean_squared_error(prediction,ground_truth))print('User based CF RMSE: '+str(rmse(user_prediction,test_data_matrix)))print('Item based CF RMSe: '+str(rmse(item_prediction,test_data_matrix)))print('User based CF RMSE: '+str(rmse(user_prediction,test_data_matrix)))print('Item based CF RMSe: '+str(rmse(item_prediction,test_data_matrix)))
输出结果:
User based CF RMSE: 3.087357412872858
Item based CF RMSe: 3.437038163412728
SVD即:奇异值分解(Singular value decomposition)奇异值分解是线性代数中一种重要的矩阵分解,在信号处理、统计学等领域有重要应用。奇异值分解在某些方面与对称矩阵或Hermite矩阵基于特征向量的对角化类似。然而这两种矩阵分解尽管有其相关性,但还是有明显的不同。对称阵特征向量分解的基础是谱分析,而奇异值分解则是谱分析理论在任意矩阵上的推广。
defload_dataset():"Load the sample dataset."return[[1,3,4],[2,3,5],[1,2,3,5],[2,5]]defcreateC1(dataset):"Create a list of candidate item sets of size one."c1=[]fortransactionindataset:foritemintransaction:ifnot[item]inc1:c1.append([item])c1.sort()#frozenset because it will be a ket of a dictionary.returnlist(map(frozenset,c1))defscanD(dataset,candidates,min_support):"Returns all candidates that meets a minimum support level"sscnt={}fortidindataset:#print(tid)forcanincandidates:ifcan.issubset(tid):sscnt.setdefault(can,0)sscnt[can]+=1num_items=float(len(dataset))retlist=[]support_data={}forkeyinsscnt:support=sscnt[key]/num_itemsifsupport>=min_support:retlist.insert(0,key)support_data[key]=supportreturnretlist,support_datadefaprioriGen(freq_sets,k):"Generate the joint transactions from candidate sets"retList=[]lenLk=len(freq_sets)foriinrange(lenLk):forjinrange(i+1,lenLk):L1=list(freq_sets[i])[:k-2]L2=list(freq_sets[j])[:k-2]L1.sort()L2.sort()ifL1==L2:retList.append(freq_sets[i]|freq_sets[j])returnretListdefapriori(dataset,minsupport=0.5):"Generate a list of candidate item sets"C1=createC1(dataset)D=list(map(set,dataset))L1,support_data=scanD(D,C1,minsupport)L=[L1]k=2while(len(L[k-2])>0):Ck=aprioriGen(L[k-2],k)Lk,supK=scanD(D,Ck,minsupport)support_data.update(supK)L.append(Lk)k+=1returnL,support_data
defgenerateRules(L,support_data,min_confidence=0.7):"""Create the association rules L: list of frequent item sets support_data: support data for those itemsets min_confidence: minimum confidence threshold """rules=[]foriinrange(1,len(L)):forfreqSetinL[i]:H1=[frozenset([item])foriteminfreqSet]print("freqSet",freqSet,'H1',H1)if(i>1):rules_from_conseq(freqSet,H1,support_data,rules,min_confidence)else:calc_confidence(freqSet,H1,support_data,rules,min_confidence)returnrulesdefcalc_confidence(freqSet,H,support_data,rules,min_confidence=0.7):"Evaluate the rule generated"pruned_H=[]forconseqinH:conf=support_data[freqSet]/support_data[freqSet-conseq]ifconf>=min_confidence:print(freqSet-conseq,'--->',conseq,'conf:',conf)rules.append((freqSet-conseq,conseq,conf))pruned_H.append(conseq)returnpruned_Hdefrules_from_conseq(freqSet,H,support_data,rules,min_confidence=0.7):"Generate a set of candidate rules"m=len(H[0])if(len(freqSet)>(m+1)):Hmp1=aprioriGen(H,m+1)Hmp1=calc_confidence(freqSet,Hmp1,support_data,rules,min_confidence)iflen(Hmp1)>1:rules_from_conseq(freqSet,Hmp1,support_data,rules,min_confidence)