The dynamic lifestyle
people lead nowadays
causes many reactions
in our bodies and
the one that is the
most frequent of all
is the headache. However so good
# Import typesfrompyspark.sql.typesimport*# Generate comma delimited datastringCSVRDD=sc.parallelize([(123,'Katie',19,'brown'),(234,'Michael',22,'green'),(345,'Simone',23,'blue')])# Specify schemaschema=StructType([StructField("id",LongType(),True),StructField("name",StringType(),True),StructField("age",LongType(),True),StructField("eyeColor",StringType(),True)])# Apply the schema to the RDD and Create DataFrameswimmers=spark.createDataFrame(stringCSVRDD,schema)# Creates a temporary view using the DataFrameswimmers.createOrReplaceTempView("swimmers")swimmers.printSchema()
spark.sql("select count(1) from swimmers").show()spark.sql("select id, age from swimmers where age = 22").show()spark.sql("select name, eyeColor from swimmers where eyeColor like 'b%'").show()
<!-- Site specific YARN configuration properties --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.address</name><value>master:8032</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>master:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value>master:8031</value></property><property><name>yarn.resourcemanager.admin.address</name><value>master:8033</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>master:8088</value></property>

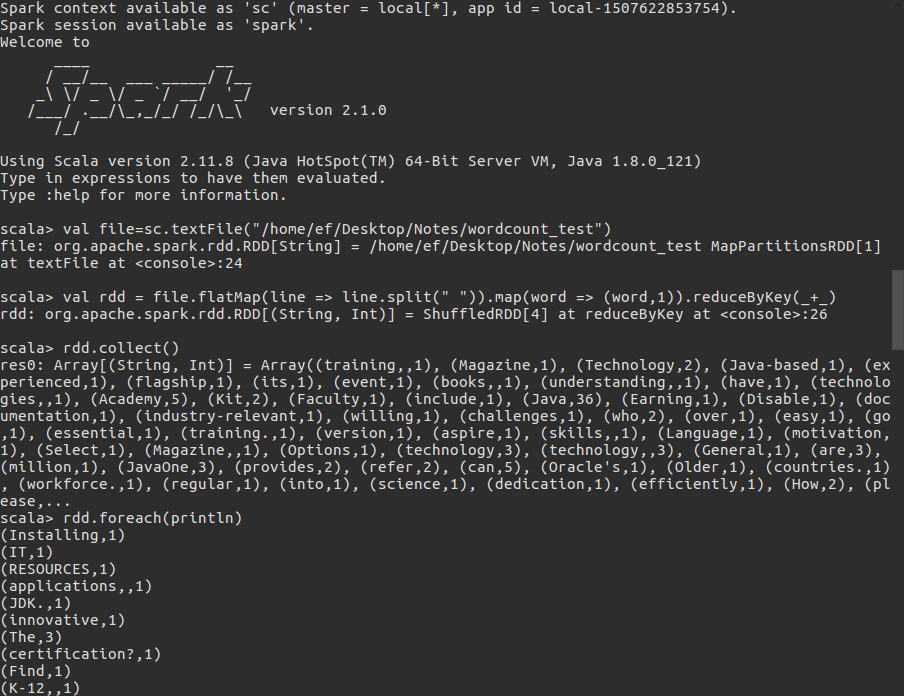

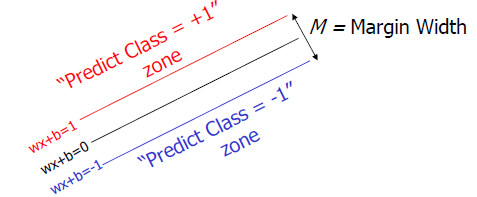



 即可。
即可。